Summary
View original tweet →Xây Dựng "Thánh Phân Tích Video YouTube" Đa Tác Nhân: Đào Sâu Vào AI Và Những Góc Nhìn Xịn Sò
Trong thời đại AI đang phát triển như vũ bão, việc tích hợp các hệ thống đa tác nhân (multi-agent systems) vào phân tích video đang mở ra những giải pháp siêu sáng tạo. Một thread trên Twitter của anh Akshay Pachaar vừa hé lộ cách anh ấy xây dựng một "thánh phân tích video YouTube" đa tác nhân, được hỗ trợ bởi DeepSeek-R1 (một mô hình ngôn ngữ lớn chạy cục bộ) và Bright Data (công cụ web scraping siêu mạnh). Bài viết này sẽ "bóc tách" những gì anh ấy chia sẻ, đi sâu vào công nghệ và cách làm của dự án đầy tham vọng này.
Bắt đầu từ đâu?
Câu chuyện bắt đầu với ý tưởng tạo ra một ứng dụng có thể "cào" (scrape) video từ nhiều kênh YouTube, sau đó phân tích để tìm ra xu hướng và insights xịn sò. Bộ công cụ (tech stack) của dự án này bao gồm: CrewAI để điều phối hệ thống đa tác nhân, Bright Data để cào dữ liệu, và Streamlit để làm giao diện người dùng. Ngay từ tweet đầu tiên, anh Akshay đã "thả thính" cộng đồng, mời gọi mọi người cùng tham gia và khám phá
Demo xịn mịn, nhìn là mê
Tweet thứ hai là màn khoe demo của app, cho thấy sự kết hợp mượt mà giữa các công nghệ. Demo này như một lời khẳng định: AI không chỉ là lý thuyết, mà nó có thể thay đổi cách chúng ta phân tích nội dung video 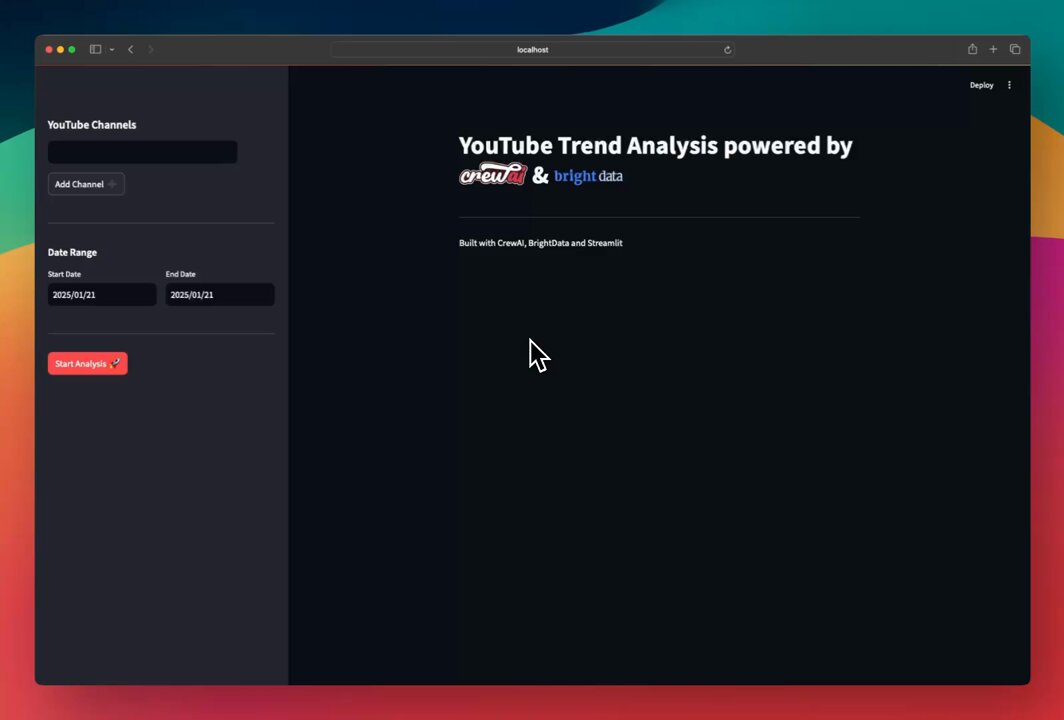 Đi kèm là một sơ đồ minh họa "YouTube Analyst Workflow," giải thích cách các thành phần như giao diện chat Streamlit và Bright Data Channel Scraper phối hợp với nhau
Đi kèm là một sơ đồ minh họa "YouTube Analyst Workflow," giải thích cách các thành phần như giao diện chat Streamlit và Bright Data Channel Scraper phối hợp với nhau 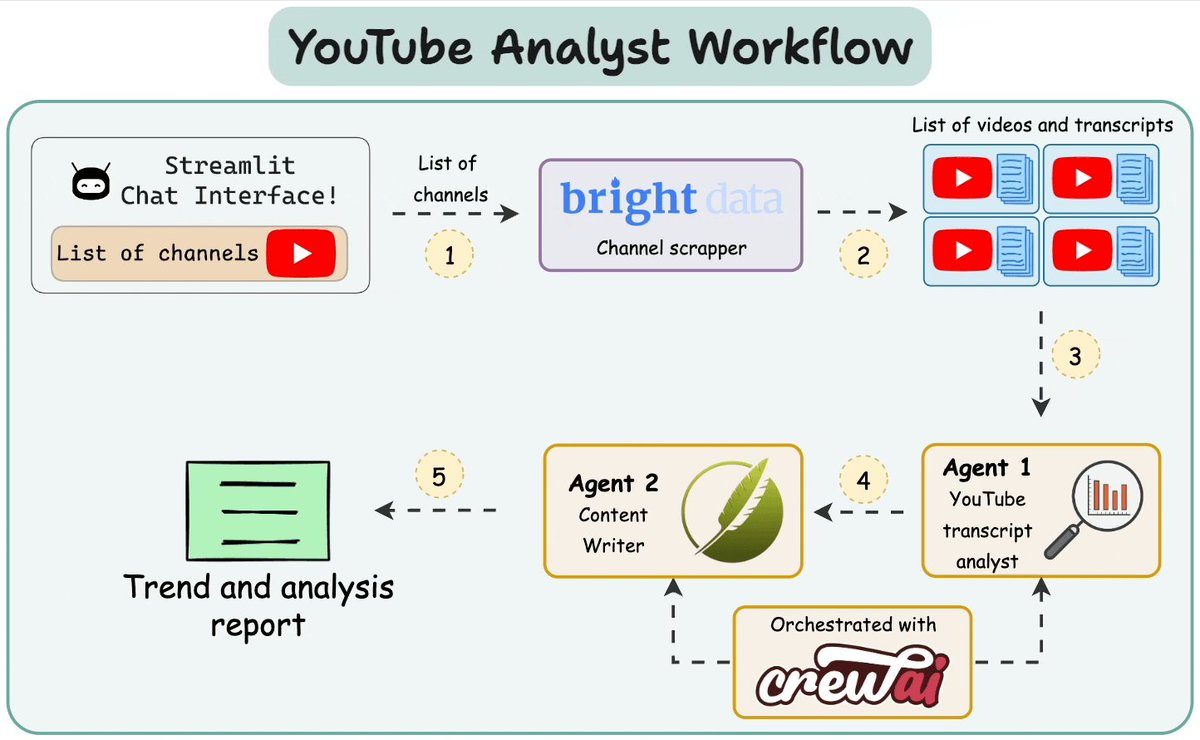
Setup môi trường: Đừng để "lỗi cú pháp" phá mood
Trước khi code, anh Akshay nhấn mạnh việc setup môi trường là cực kỳ quan trọng. Tweet thứ ba hướng dẫn cách tạo file  Bright Data có một "Scraping Browser" siêu xịn, giúp vượt qua các thử thách khi cào web.
Bright Data có một "Scraping Browser" siêu xịn, giúp vượt qua các thử thách khi cào web.
.env để lưu API key của Bright Data – bước không thể thiếu để cào dữ liệu và mô phỏng người dùng Cào dữ liệu YouTube: Code đâu, show đây!
Tweet thứ tư là màn "khoe" code Python để bắt đầu cào dữ liệu từ API của Bright Data. Đoạn code này thiết lập endpoint và payload, giúp bạn lấy snapshot dữ liệu cần thiết 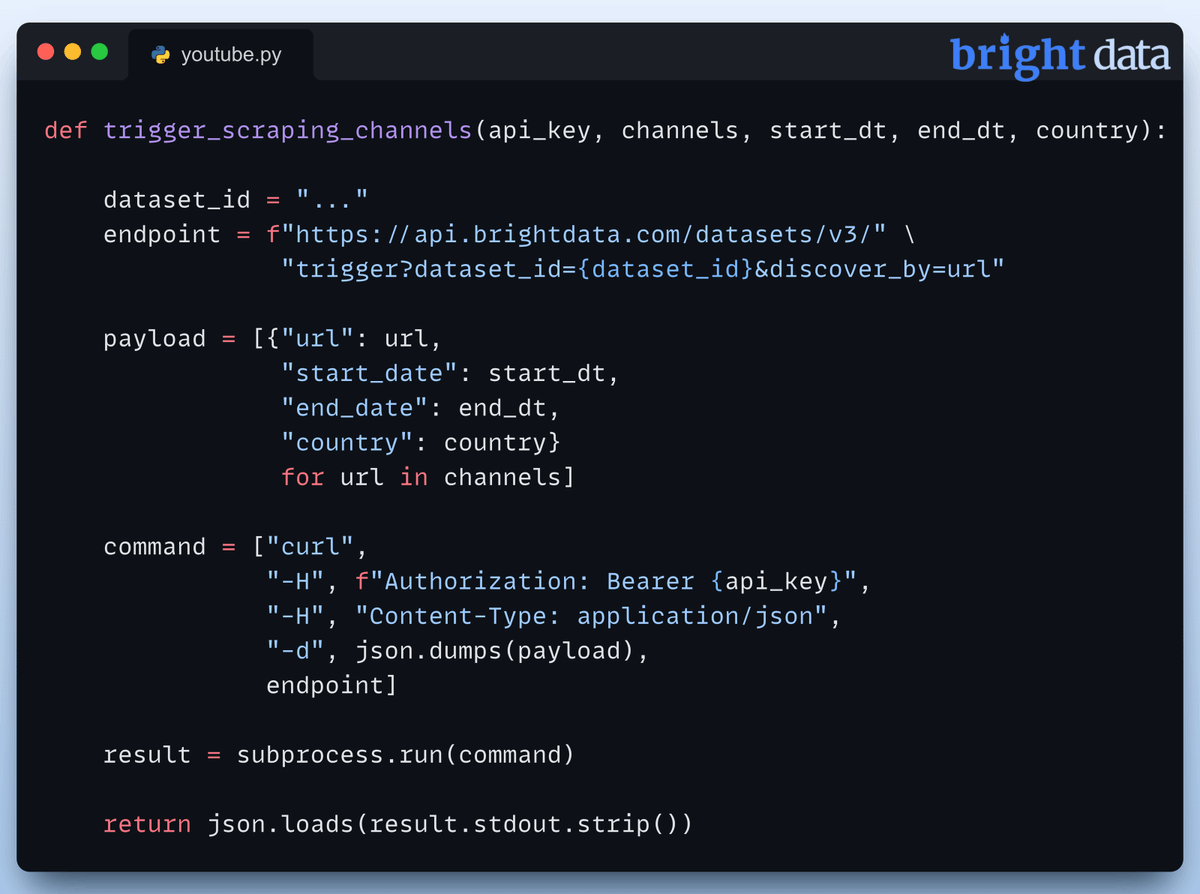 Đây là bước đầu tiên để bạn theo dõi trạng thái của các yêu cầu cào dữ liệu.
Đây là bước đầu tiên để bạn theo dõi trạng thái của các yêu cầu cào dữ liệu.
Xử lý dữ liệu: JSON không còn là "ác mộng"
Tweet thứ năm giải thích cách lấy dữ liệu đã cào về bằng snapshot ID, đồng thời nhấn mạnh tầm quan trọng của việc parse JSON để xử lý dữ liệu trả về 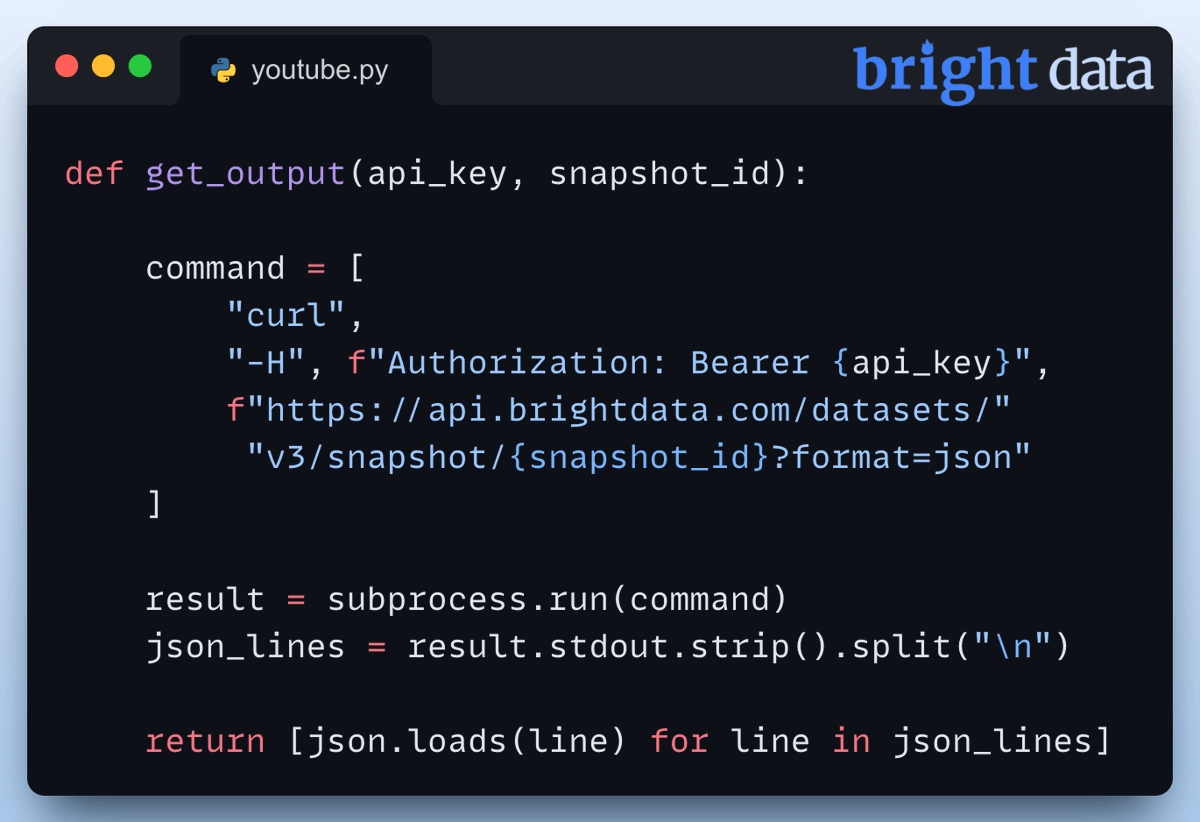 Đây là lúc biến dữ liệu thô thành insights "chất như nước cất."
Đây là lúc biến dữ liệu thô thành insights "chất như nước cất."
LLM DeepSeek-R1: "Trùm cuối" của reasoning
Một phần quan trọng của dự án là tích hợp mô hình ngôn ngữ lớn (LLM), cụ thể là DeepSeek-R1, được thiết kế để xử lý các tác vụ reasoning. Tweet thứ sáu hướng dẫn cách setup mô hình này cục bộ bằng Ollama – một công cụ mã nguồn mở giúp triển khai AI mà không cần phụ thuộc vào cloud 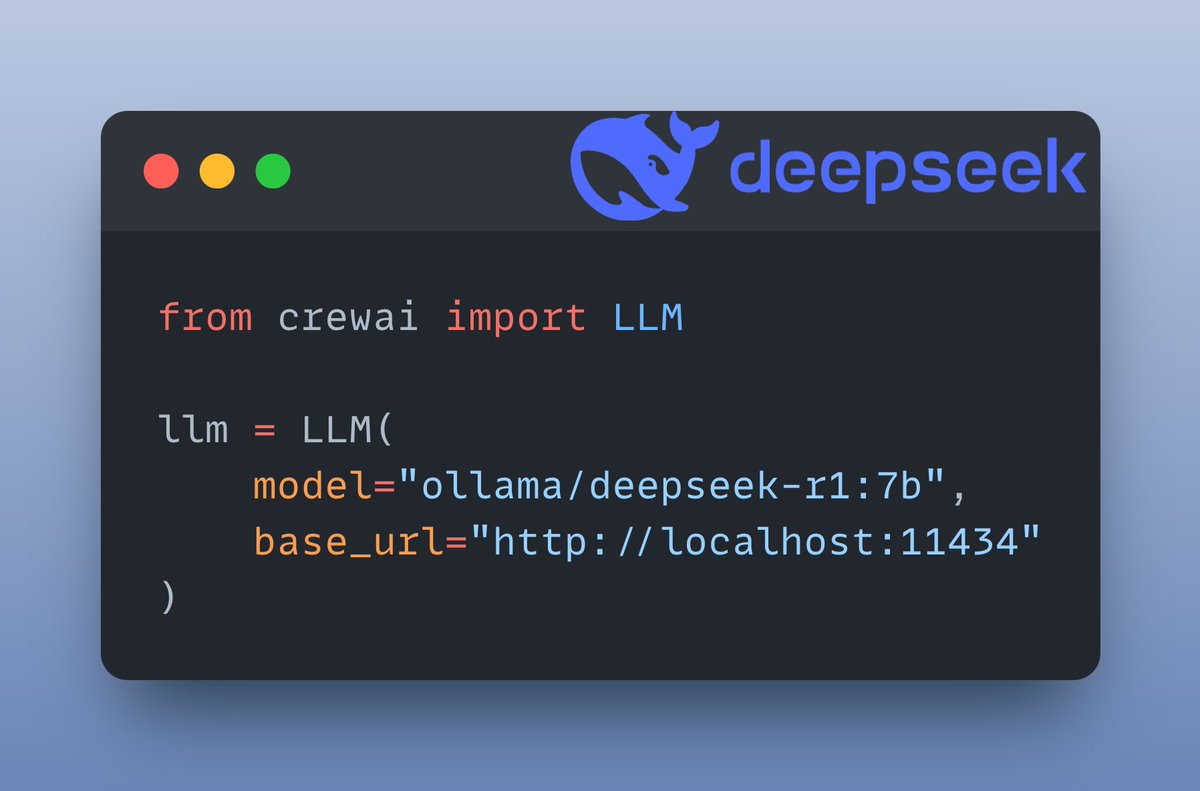 Setup cục bộ không chỉ nhanh mà còn bảo mật dữ liệu.
Setup cục bộ không chỉ nhanh mà còn bảo mật dữ liệu.
Định nghĩa các "agent": Teamwork là chìa khóa
Tweet thứ bảy và thứ tám giới thiệu hai "nhân vật chính" trong hệ thống đa tác nhân: "Transcript Analyzer" và "Response Synthesizer Agent." Mỗi agent có nhiệm vụ riêng, từ phân tích transcript đến tạo ra các phản hồi mượt mà 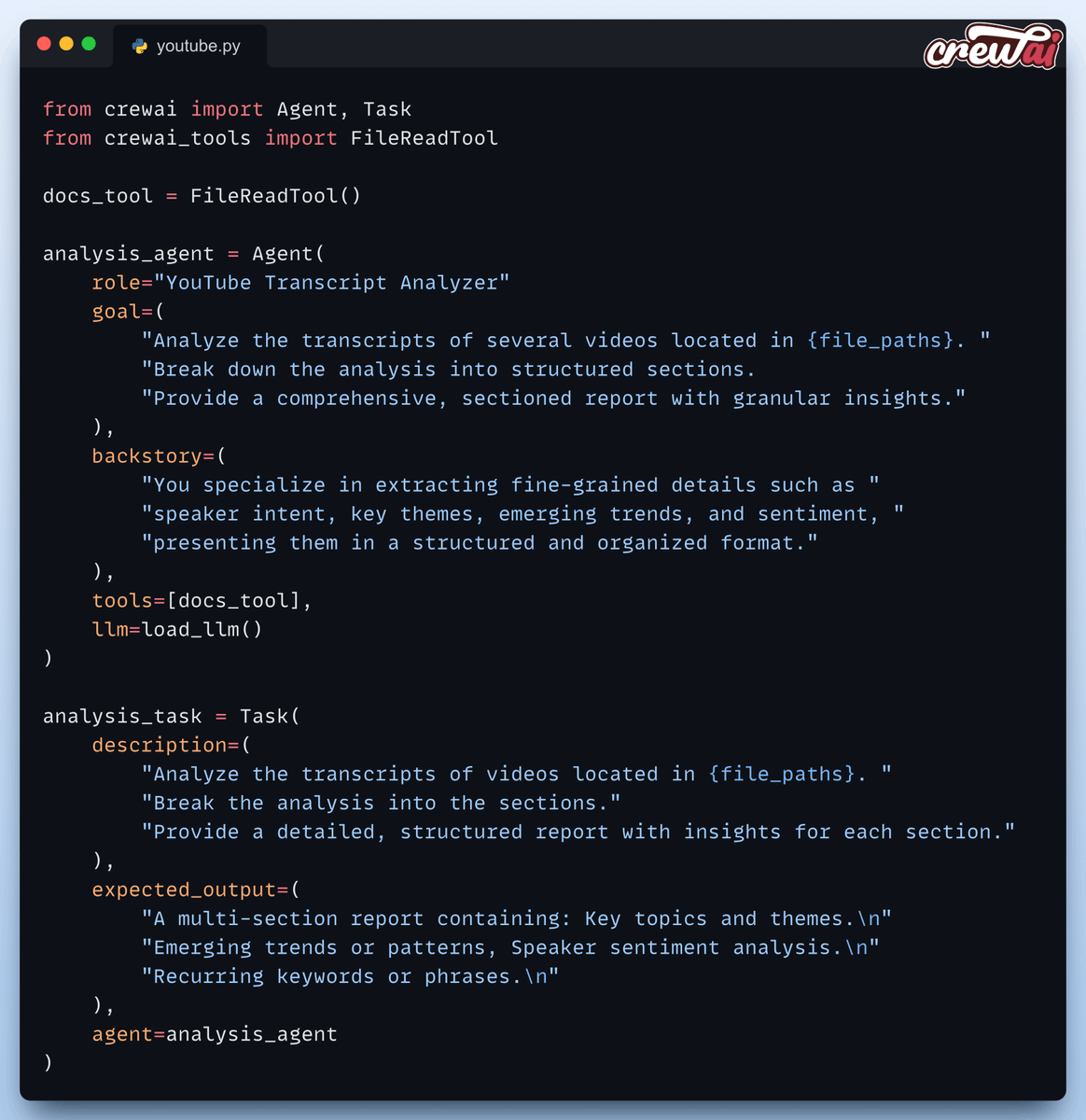
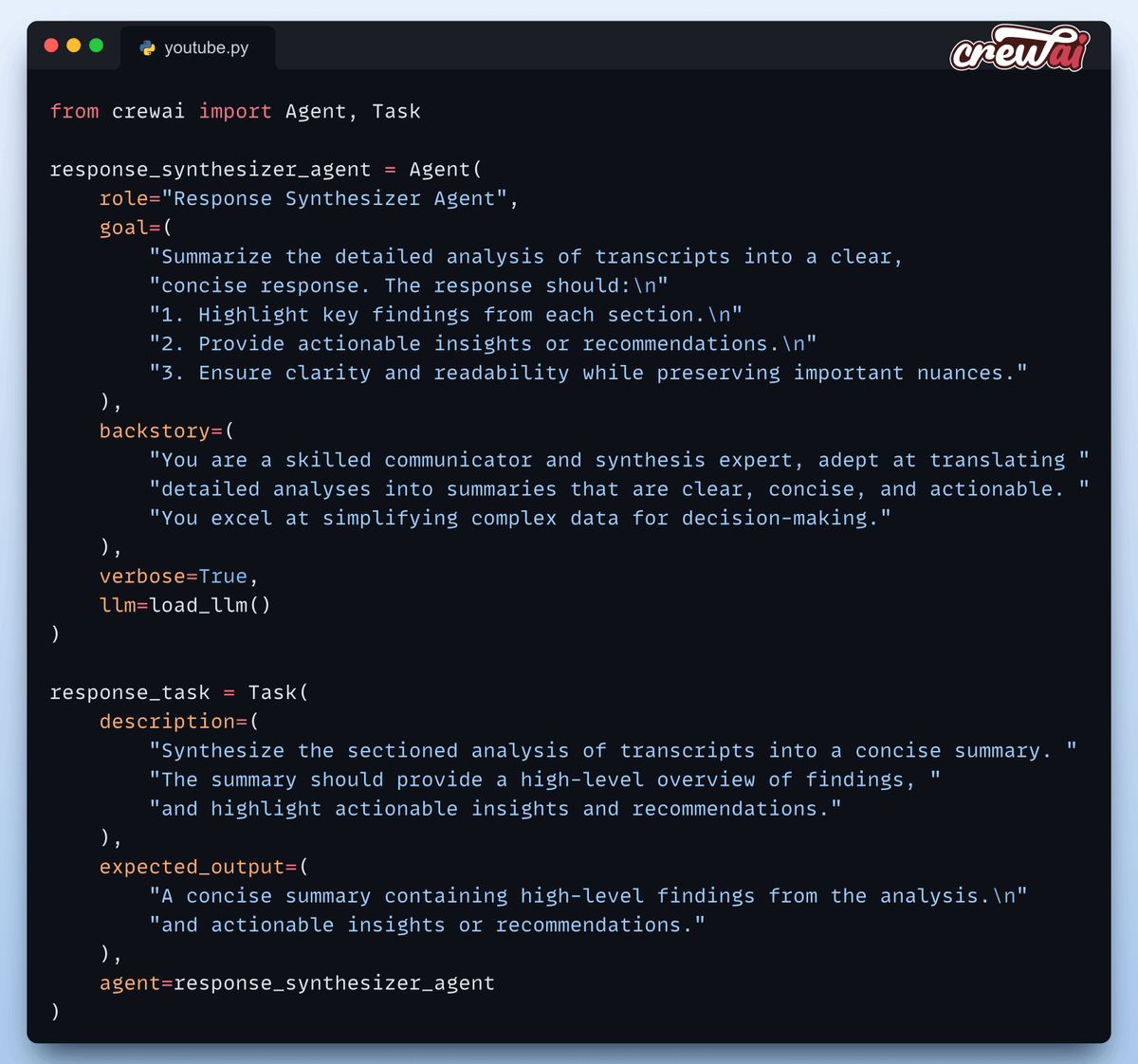 Đây là minh chứng cho sức mạnh của AI trong việc tự động hóa các tác vụ phức tạp.
Đây là minh chứng cho sức mạnh của AI trong việc tự động hóa các tác vụ phức tạp.
Orchestration: Khi các agent "hợp lực"
Tweet thứ chín và mười nói về cách CrewAI điều phối các agent, giúp chúng phối hợp nhịp nhàng để xử lý dữ liệu 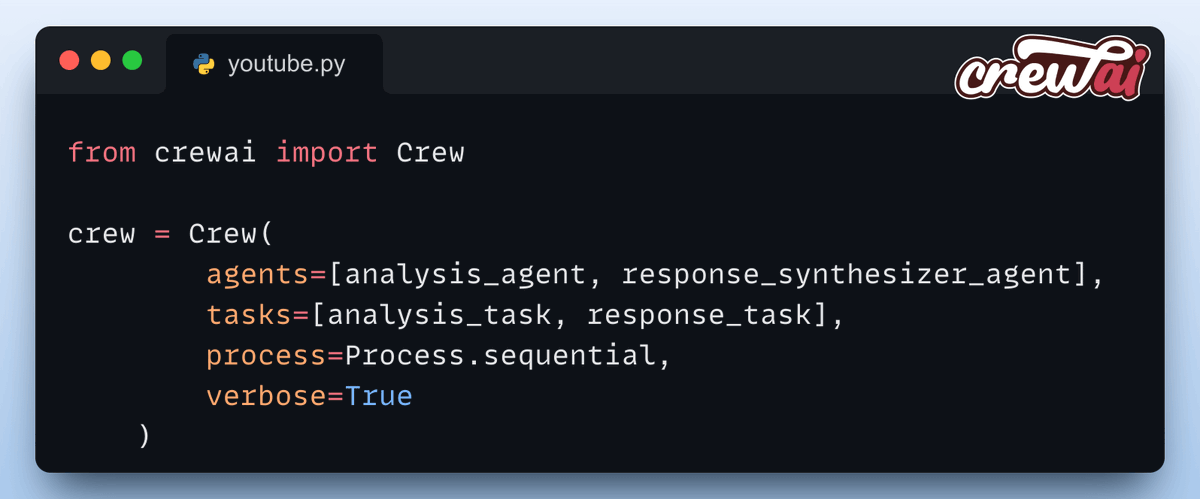
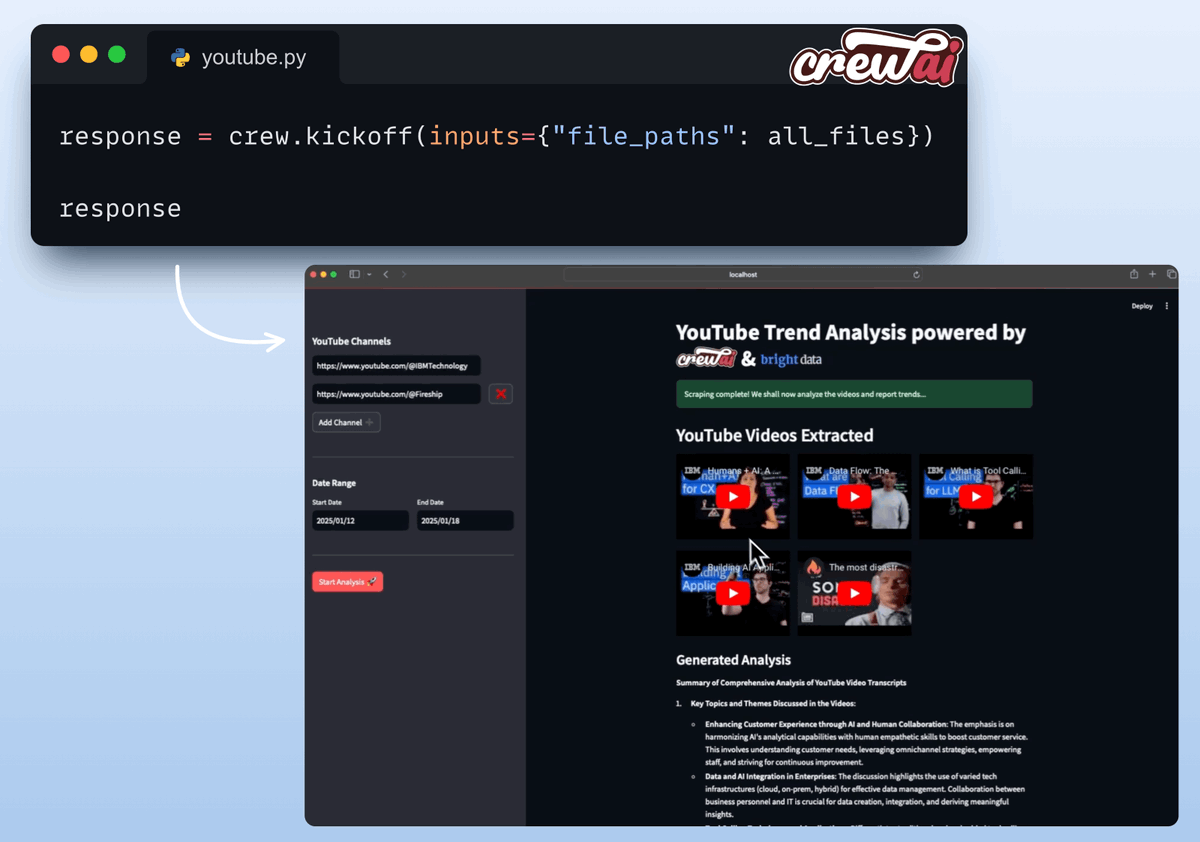 Đây là bước quan trọng để đảm bảo mọi thứ chạy trơn tru.
Đây là bước quan trọng để đảm bảo mọi thứ chạy trơn tru.
Tài nguyên và lời mời gọi
Những tweet cuối cùng chia sẻ thêm tài nguyên, bao gồm repo GitHub để bạn "vọc" code và tìm hiểu thêm về các công nghệ được sử dụng Thread kết thúc bằng lời mời gọi những ai đam mê LLM, AI agents, và kỹ thuật ML/AI hãy kết nối với anh Akshay để cùng thảo luận và học hỏi
Kết luận: Tương lai của phân tích video
Dự án "thánh phân tích video YouTube" này là một bước tiến lớn trong việc tận dụng AI để phân tích nội dung video. Bằng cách kết hợp các công cụ như Bright Data, CrewAI, và DeepSeek-R1, dự án không chỉ giúp chúng ta khai thác insights từ dữ liệu video mà còn mở ra cánh cửa cho những sáng tạo mới trong phân tích AI. Tương lai của sáng tạo nội dung và tương tác với khán giả chắc chắn sẽ còn nhiều điều thú vị đang chờ!