Summary
View original tweet →Tầm Quan Trọng Của Data Orchestration Trong Quy Trình Hiện Đại
Trong thế giới "nghiện data" ngày nay, việc quản lý và điều phối các pipeline dữ liệu một cách hiệu quả đang ngày càng trở nên quan trọng. Một thread trên Twitter của anh @svpino vừa "bóc phốt" chủ đề này, nhấn mạnh tầm quan trọng của kỹ năng xử lý dữ liệu và các công cụ giúp đơn giản hóa quy trình này. Thread này chia sẻ bài học từ cách DeepSeek quản lý dữ liệu và giới thiệu Kestra, một nền tảng orchestration mã nguồn mở giúp việc tạo và quản lý các workflow dữ liệu trở nên dễ như ăn kẹo.
Điểm nhấn chính của bài viết là câu chốt: "Nếu chỉ học được một thứ, hãy tập trung học cách xử lý dữ liệu, xây dựng pipeline orchestration, và làm mọi thứ ở quy mô lớn." Nghe ngầu không? Nhưng mà đúng thật, đây chính là tinh thần của quản lý dữ liệu hiện đại. Khả năng xử lý và cung cấp dữ liệu hiệu quả có thể giúp các tổ chức "vượt mặt" đối thủ trong một thế giới cạnh tranh khốc liệt. Thread này cũng tóm gọn ba bước cơ bản trong data orchestration: lấy dữ liệu từ nguồn (Extract), xử lý và làm sạch (Transform), rồi chuyển dữ liệu sạch đến nơi cần thiết (Load). Dân tech chắc không lạ gì với thuật ngữ ETL này rồi, đúng không?
Để minh họa sức mạnh của Kestra, anh @svpino còn "khoe" một tấm screenshot giao diện của nó, cho thấy một workflow editor cho phép người dùng định nghĩa và quản lý pipeline dữ liệu bằng YAML. Nhìn giao diện mà mê luôn, vừa thân thiện vừa giúp teamwork dễ dàng hơn. Hình ảnh cho thấy một giao diện tối màu (dark mode là chân ái), với các tùy chọn quản lý flows, executions, và tasks. Đúng kiểu "chân ái" cho các bạn dev và data engineer. 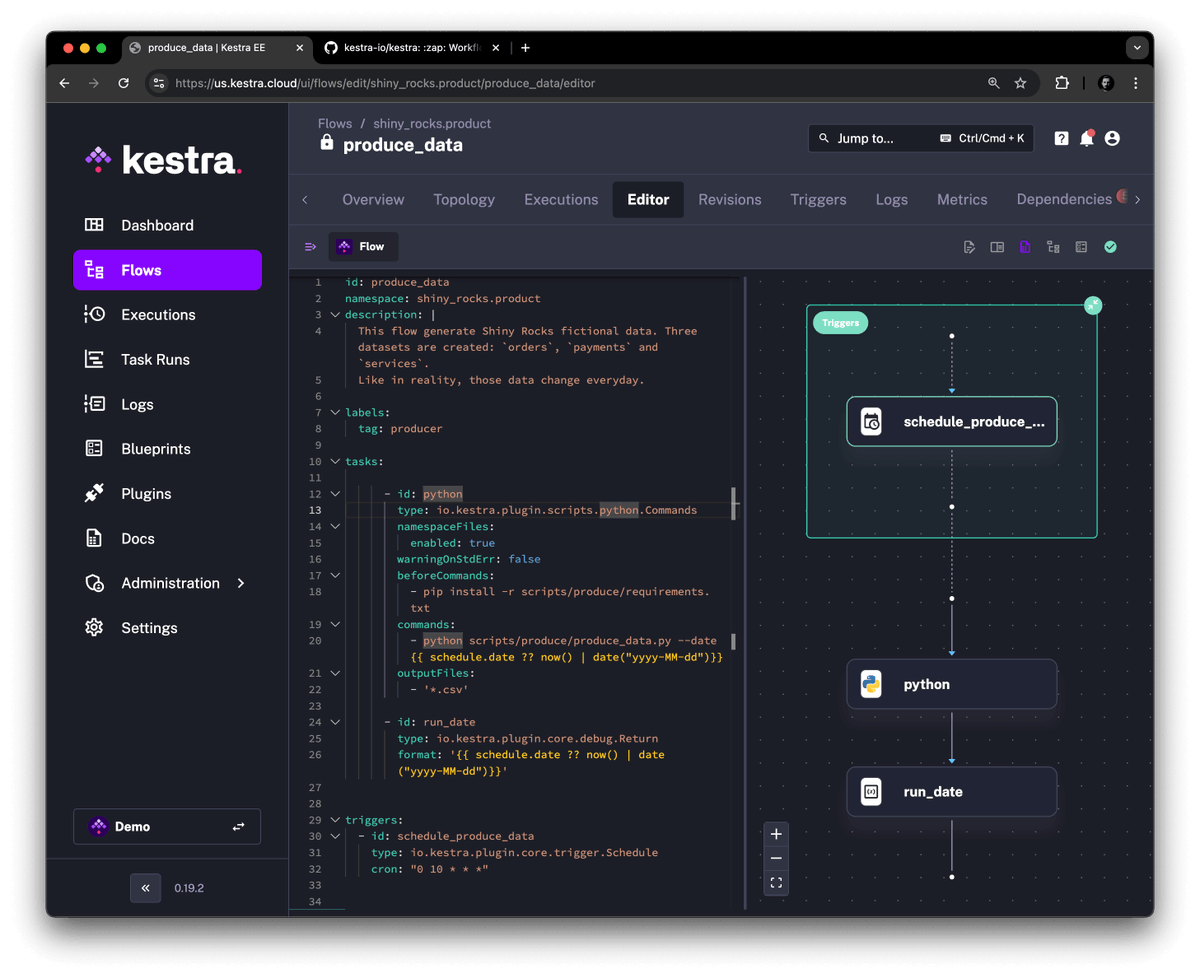
Một điểm sáng khác của Kestra là kiến trúc event-driven. Nghe thì hơi "hàn lâm", nhưng hiểu đơn giản là các workflow có thể tự động kích hoạt dựa trên các sự kiện như upload file hay cập nhật database. Quá tiện cho việc tạo ra các hệ thống phản ứng nhanh với thay đổi dữ liệu trong thời gian thực. Nhưng mà, không phải lúc nào cũng "màu hồng", vì kiểu này cũng dễ gặp mấy vấn đề như mất dữ liệu hay xử lý sai thứ tự. Ai mà xử lý ngon mấy vụ này thì đúng là "trùm cuối" trong làng data orchestration luôn.
Trong một tweet tiếp theo, anh @svpino còn "thả link" GitHub của Kestra, mời mọi người vào "vọc" thử. Đây cũng là minh chứng cho xu hướng ngày càng phổ biến của các giải pháp mã nguồn mở trong quản lý dữ liệu. Vừa linh hoạt, vừa có cộng đồng hỗ trợ, quá hời luôn!
Bài viết cũng nhấn mạnh ý nghĩa lớn hơn của việc thành thạo kỹ năng data orchestration. Khi các tổ chức ngày càng dựa vào dữ liệu để ra quyết định, nhu cầu về những người có thể thiết kế các hệ thống bền bỉ, mở rộng được, và chống lỗi ngày càng tăng. Kỹ năng xây dựng và quản lý pipeline dữ liệu không chỉ là một kỹ năng kỹ thuật, mà còn là một lợi thế chiến lược, giúp tăng hiệu quả và thúc đẩy đổi mới.
Tóm lại, những chia sẻ trong thread của anh @svpino là một lời nhắc nhở quý giá về tầm quan trọng của data orchestration trong quy trình hiện đại. Khi chúng ta tiếp tục "vật lộn" với sự phức tạp của quản lý dữ liệu, những công cụ như Kestra sẽ đóng vai trò quan trọng trong việc định hình tương lai của xử lý dữ liệu. Đầu tư vào kỹ năng để làm chủ những công cụ này, bạn sẽ tự đặt mình vào vị trí "đầu tàu" trong thế giới tích hợp dữ liệu và AI đang phát triển từng ngày.